
Notice
Recent Posts
Recent Comments
목록클러스터링 (1)
Data Analysis for Investment & Control
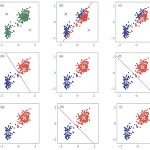 K-means Clustering
K-means Clustering
클러스터링 기법 중에 대표되는 것으로 다차원 입력 데이터를 어떻게 어떤 그룹에 속하게 할지에 대한 문제를 다룬다. 데이터의 집합을 정의하자. N개로 이루어져 있는 데이터를 K개의 클러스터로 분류하려고 한다(물론 K는 미리 지정한다). K개의 클러스터 정 중앙에 놓여 있는 값을 μk라고 표기 한다. K-means 클러스터링의 아이디어는 K개의 mean(중앙 값)을 이용해 클러스터링 하는 것이다. μk와 이에 속하는 클러스터 데이터 사이의 거리의 총합은 클러스터에 속하지 않는 데이터 사이의 거리의 총합보다 작다. 그러므로 우리의 목표는 주어진 데이터 집합으로부터 이러한 중심 μk의 값을 결정하는 것이다. N개의 데이터를 K개의 클러스터로 구분지어 Sk = {S1, S2, ... SK}의 데이터 집합으로 구분..
MachineLearning/Clustering
2018. 11. 28. 00:10